DIRK BAKOWIES | HOME PAGE

Tel: +41 78 856 61 45 |
| Welcome to Dirk's homepage | ||||||
|
Research Interests |
|
|
|
Selected recent and past projects |
|
|
|
|
|
Water cavities | ||||
|
|
FABP | |||||
|
|
Carbopeptoids | |||||
|
|
Enzymes & Free Energies | |||||
|
|
||||||
|
|
|
Cavity analysis | ||||
|
|
Pair list algorithms | |||||
|
Experience |
|
|
CBS extrapolation | |||
|
|
ATOMIC | |||||
|
|
Error and uncertainty (1) | |||||
|
|
Error and uncertainty (2) | |||||
|
|
ATOMIC-2 | |||||
|
|
||||||
|
|
|
Giant Fullerenes | ||||
|
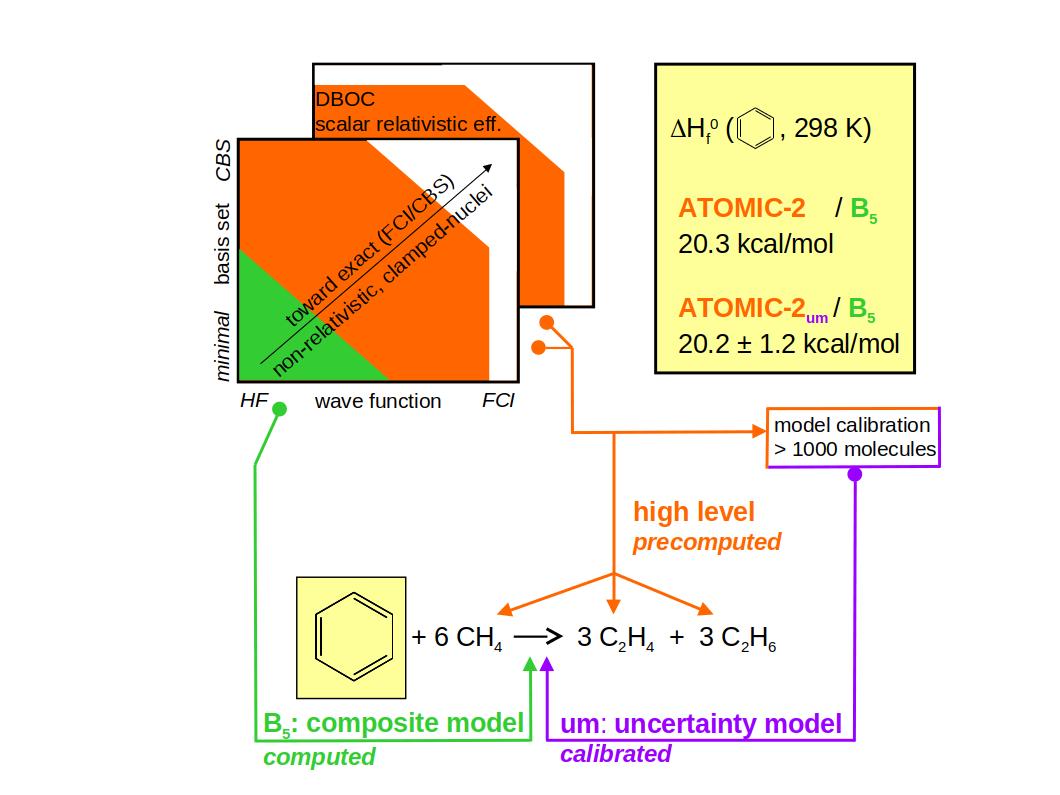
Ab initio thermochemistry: The ATOMIC-2 protocol with estimates of error and uncertainty |
ATOMIC-2 is the latest version of the ATOMIC protocol that implements Pople's
concept of bond separation reactions to reduce the error of midlevel ab initio
approaches in calculations of atomization energies and enthalpies of formation.
The new protocol focuses on computational efficiency and increased accuracy;
it retains the overall
concept and all previously defined composite models, but improves on ATOMIC-1 in
various other ways: |
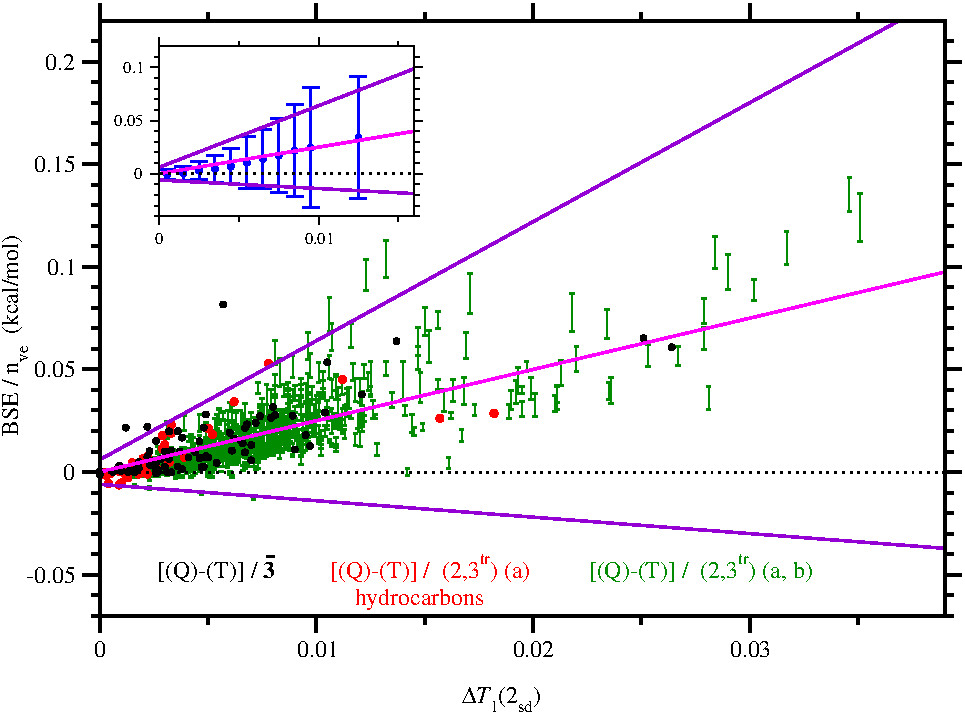
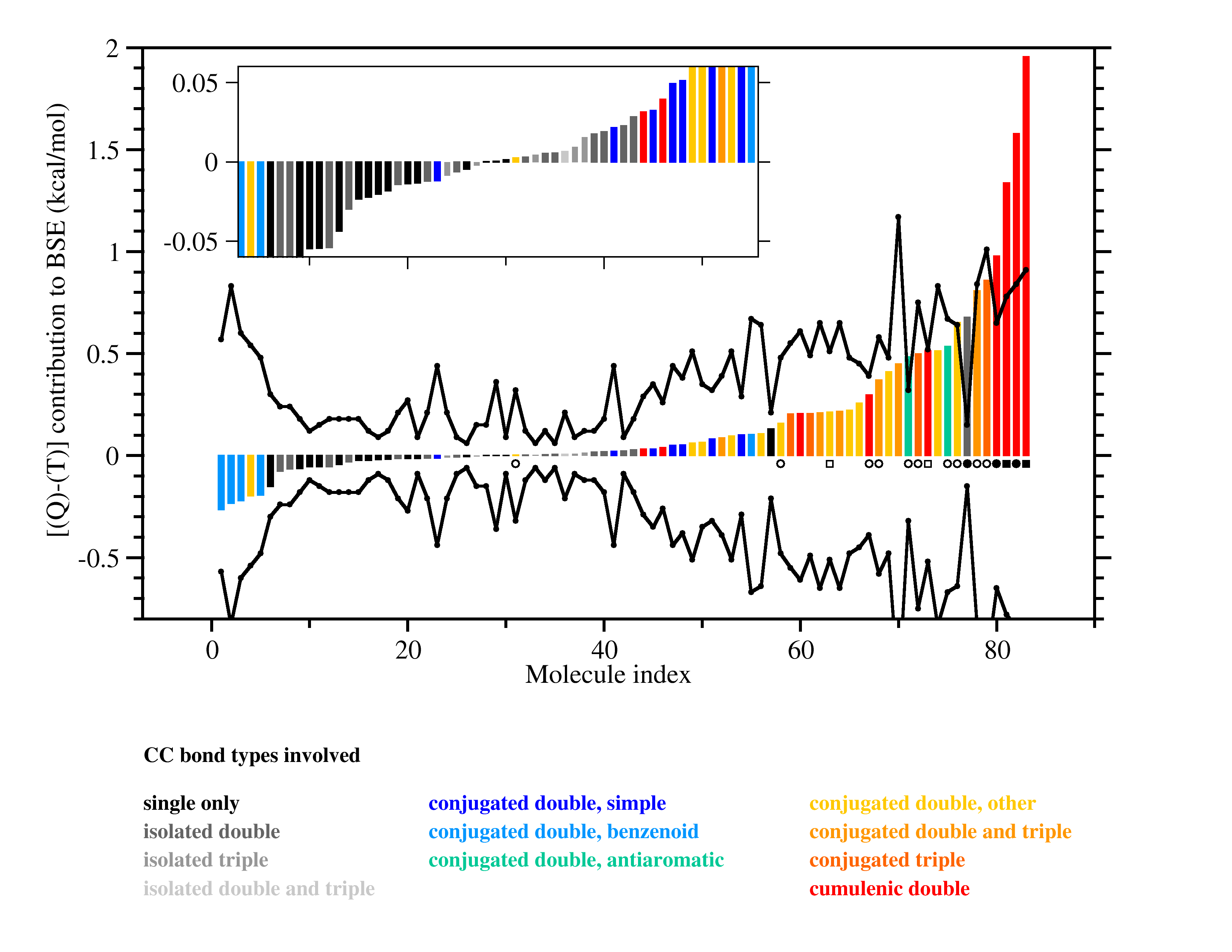
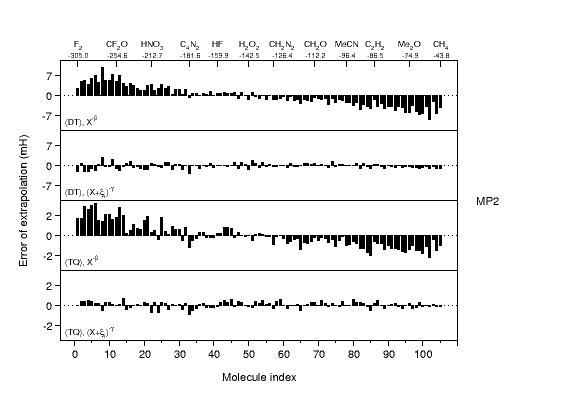
Estimate of higher-order electron correlation effects. Higher-order electron correlation effects (beyond CCSD(T)) are notoriously difficult to calculate and cannot be obtained in any thermochemistry protocol that is focused on computational efficiency. These effects can, however, make significant contributions, typically up to about 0.1 kcal/mol per correlated valence electron for moderate to severe multi-reference cases, which amounts to more than 1 kcal/mol for a small to medium-sized molecule. The figure demonstrates that the excess T1 diagnostic, available without further quantum-chemical calculation, is a valuable estimator of the expected higher-order electron correlation effect. Magenta and violet lines show the esimtated correction and uncertainty, respectively, predicted by ATOMIC-2um for the neglect of higher- order electron correlation contributions.
Computational efficiency.
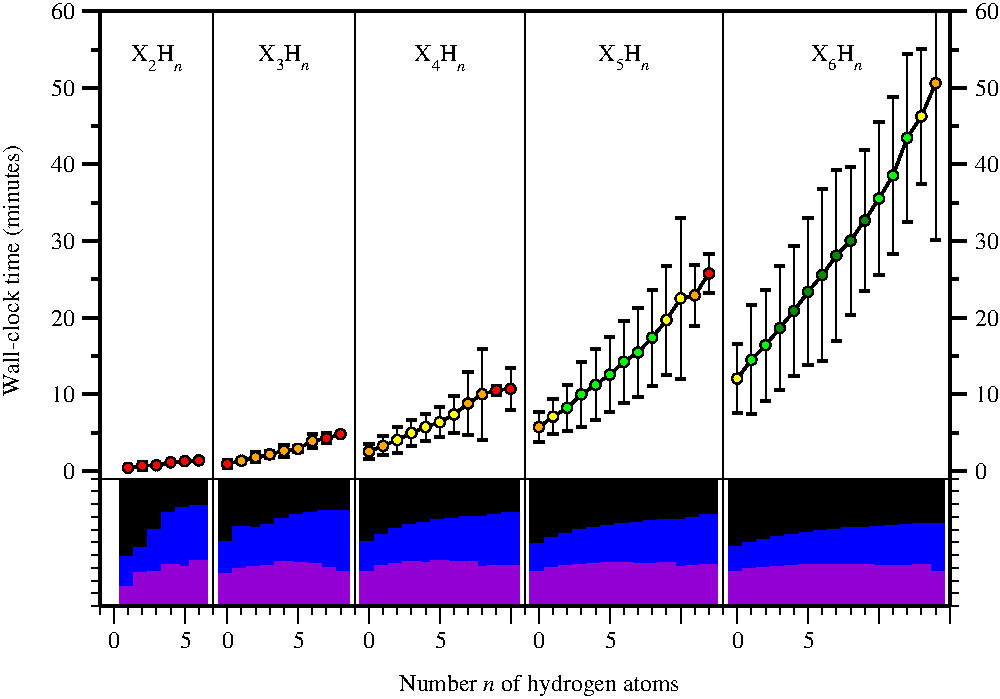
ATOMIC-2 / B5 single-core (Xeon E5-26xx) running times as observed for 248'972 molecules or conformers HnCaNbOcFd (2 <= a+b+c+d <= 6), taken from work to be published. Molecules are grouped by numbers of non-hydrogen
(X = C, N, O, F) and hydrogen atoms (n); average running times are shown along with two standard
deviations. Colors indicate the number of molecules per data point: up to 10 (red), 100 (orange), 1000
(yellow), 10000 (green), or more (dark green). The bottom panels indicate the average fraction of time
spent on geometry optimizations and frequency calculations (violet), MP2 (blue), and coupled cluster
calculations (black) needed for a full ATOMIC-2 / B5 evaluation. See the paper for details. |
|
Ab initio thermochemistry: Estimates of error and uncertainty (1) |
In experimental thermochemistry it is accepted standard to
report results together with uncertainties, usually taken to be
intervals of 95% confidence. The predictive power of theoretical
procedures is routinely assessed by comparison to sets of known
experimental results, however, it is still uncommon to augment
theoretical predictions with fair estimates of uncertainty.
A number of questions arise that may be difficult to answer: Is
the benchmark representative enough to allow for meaningful
error estimates outside? How do we account for the expected
scaling of error with molecular size?
|
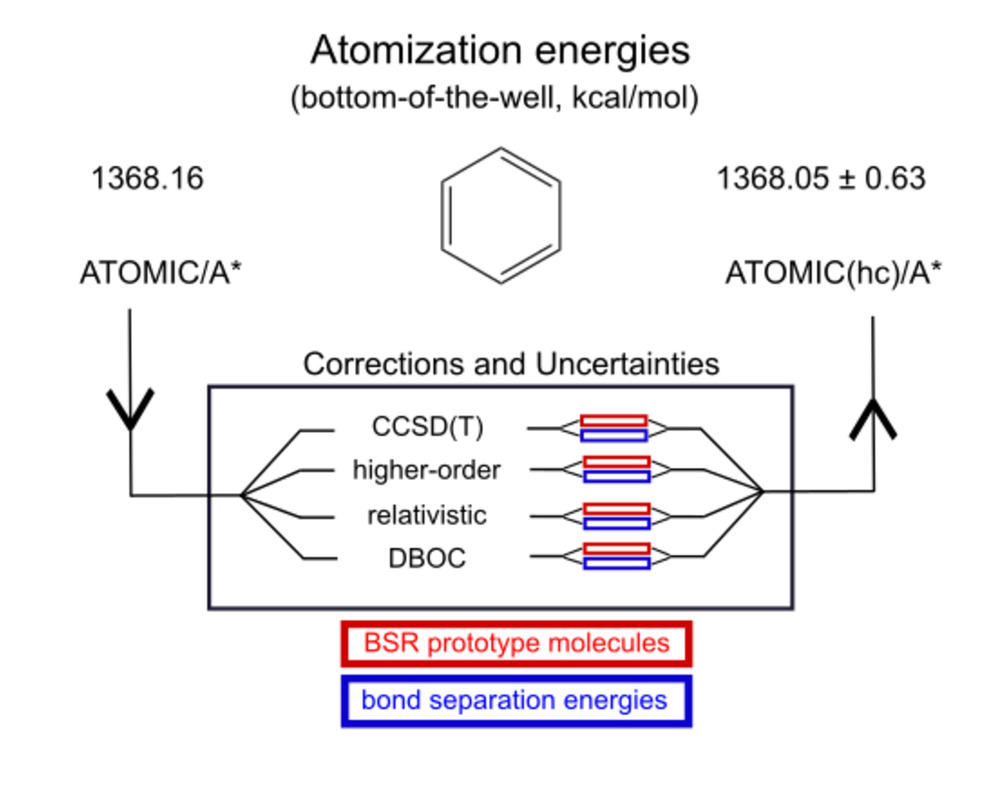
The graphic above shows that post-CCSD(T) effects can be quite sizeable, but
it also indicates that simple uncertainty estimates (black lines) manage to
cover most of the systems. A quality criterion computed from the T1 diagnostic
warns of cases for which the error estimate may be unreliable (black circles).
Other sources of error are studied as well, including the limited accuracy of
complete-basis-set extrapolations of CCSD(T) and of computed relativistic effects and
diagonal Born-Oppenheimer corrections.
|
|
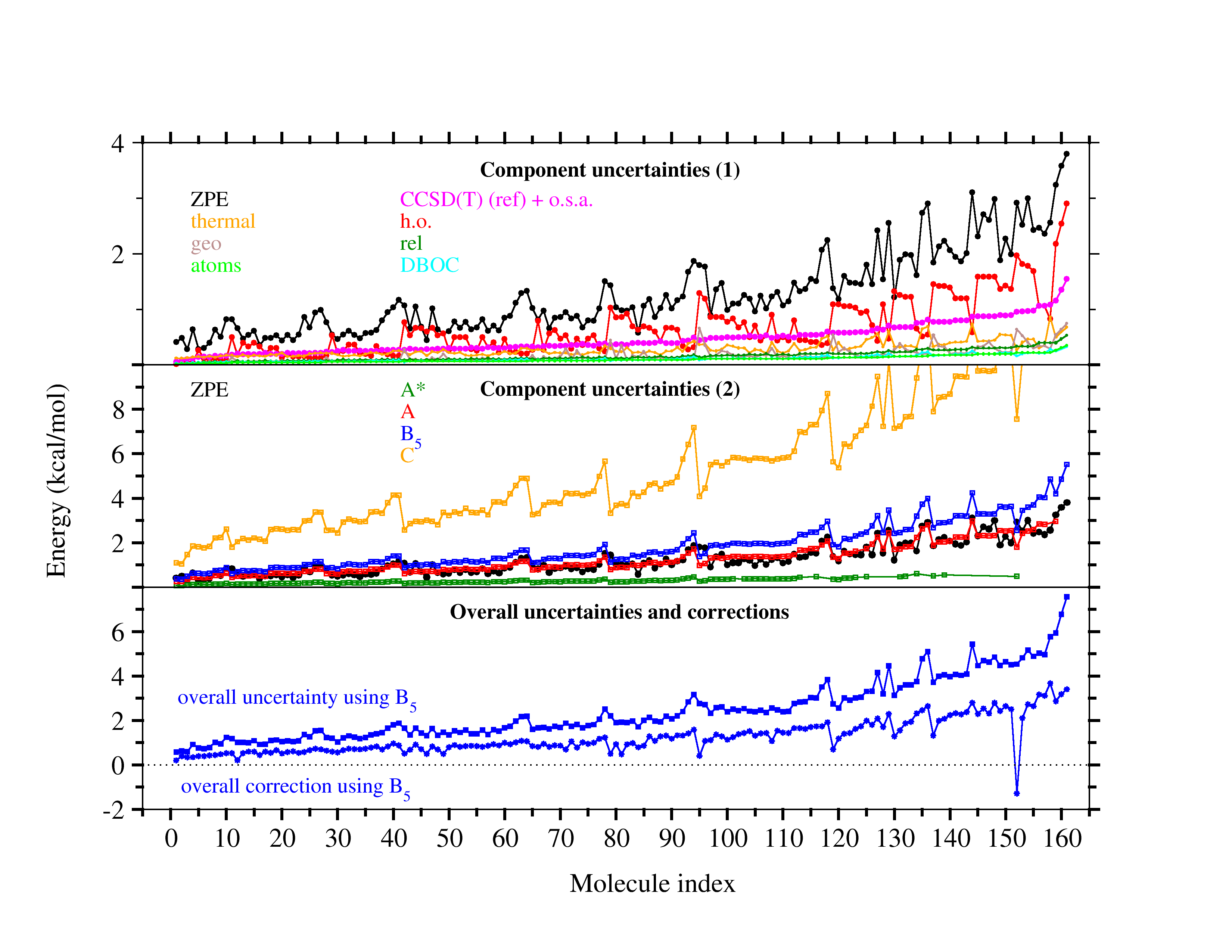
Ab initio thermochemistry: Estimates of error and uncertainty (2) |
In an extension to the ATOMIC(hc) model for bottom-of-the-well
atomization energies, we have also studied errors and uncertainties for
the remaining components necessary to evaluate
enthalpies of formation.
|
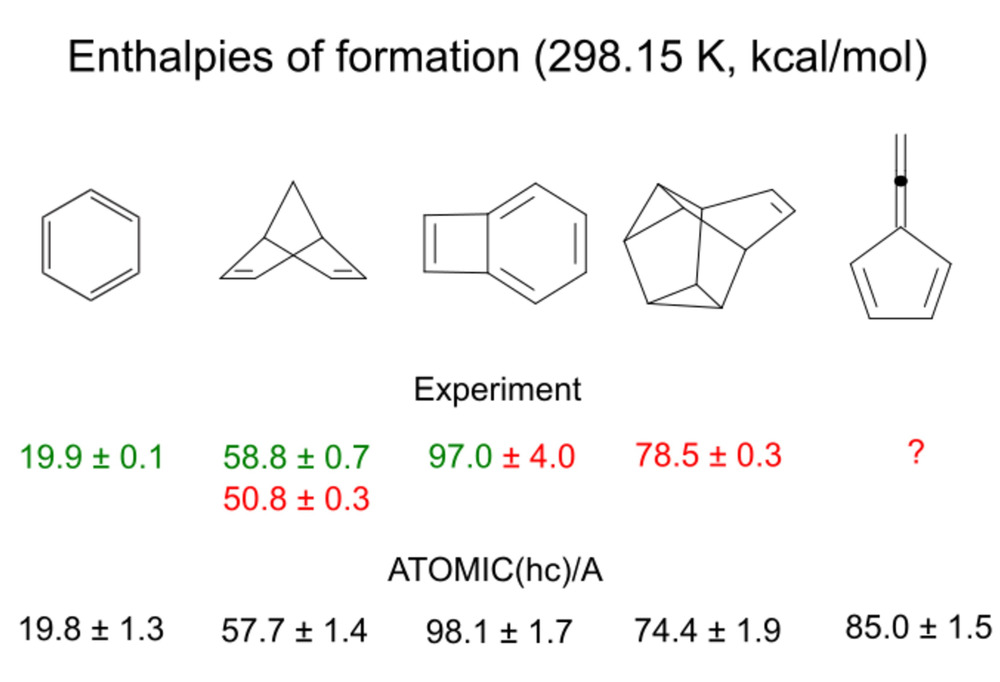
The evaluation of ZPEs from scaled harmonic frequencies (black in top graph) expectedly
emerges as the leading source of uncertainty if highly accurate composite models are
used to treat the electronic problem (such as A*, green, vs ZPE, black, in center graph),
but uncertainties are usually balanced with those from computationally more attractive
B level models (such as B5, blue, center graph) to estimate the CBS limit of CCSD(T).
|
|
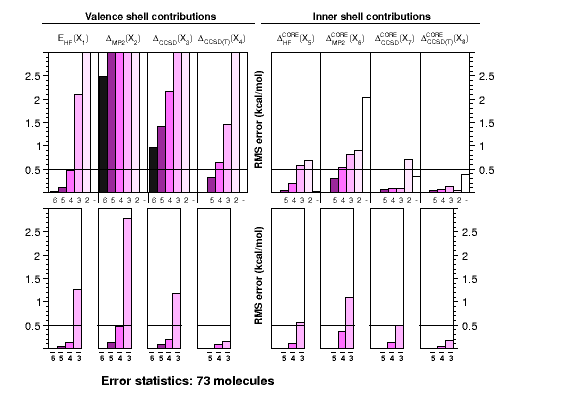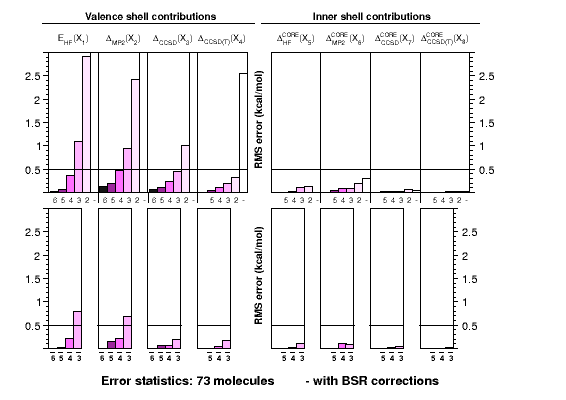
Ab initio thermochemistry: ATOMIC protocol |
The ATOMIC approach
was developed with the needs in mind that are posed by the
calibration of modern approximate models of quantum
chemistry, such as semiempirical methods. It is a robust
and computationally efficient approach to otherwise dauntingly
expensive calculations of atomization energies. The graph shows
how the use of bond separation reactions (BSRs) helps to reduce
errors in each of the components contributing to the CCSD(T)(full)
atomization energy at the complete-basis set limit. Each single
chart shows RMS errors for a particular component as function of
the basis-set cardinal number, without (top) or with (bottom)
extrapolation. In practice only small basis-set calculations
are feasible for larger systems.
|
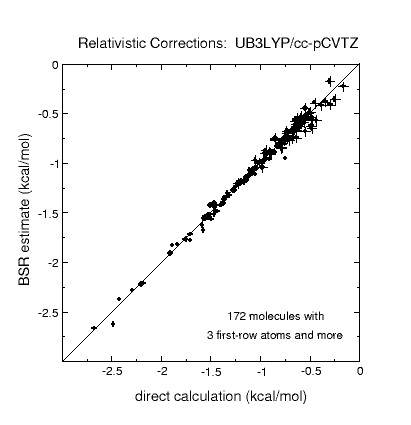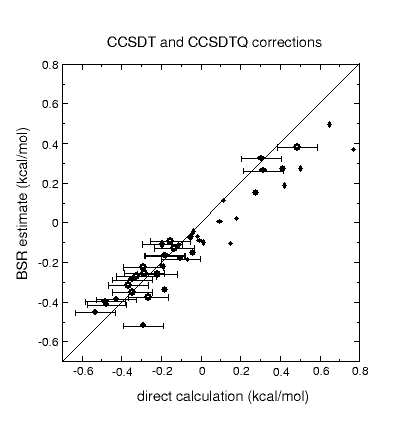
Corrections to atomization energies beyond the CCSD(T) level of theory are
estimated from thermoneutral BSRs. This simplification renders the calculation
of these corrections a trivial task of summing up bond increments. Such an
approach is astonishingly accurate for scalar relativistic corrections and
works reasonably well even for CCSDTQ-CCSD(T) corrections.
|
|
Ab initio thermochemistry: CBS extrapolation |
The development of accurate
extrapolation formulas for electron correlation energies is
an important field in ab initio thermochemistry. Electron correlation
energies are known to converge slowly to the complete basis set
limit, and finite basis set calculations will thus carry substantial
error. On the other hand, computational restraints usually force one
to resort to small basis-set calculations. The graph compares
residual errors for our newly developed and theoretically
well-motivated extrapolation formula (2nd and 4th panel) to those of
the best alternative formulations (1st and 3rd panels). The large
improvement is expected to have a significant impact on producing
reliable ab initio reference data for the calibration of empirical
and semiempirical potentials. |
|
Biomolecular simulation: Algorithms for trajectory analysis |
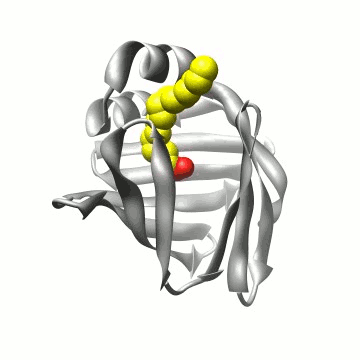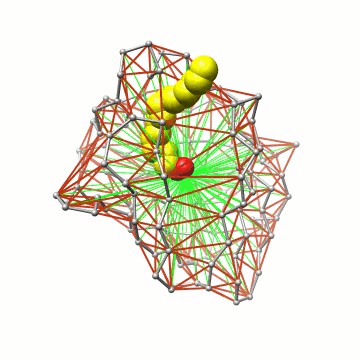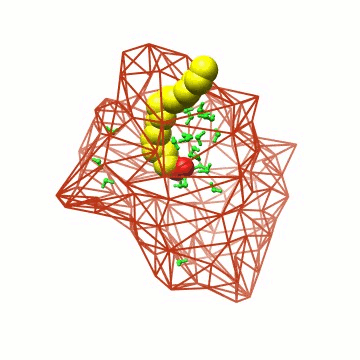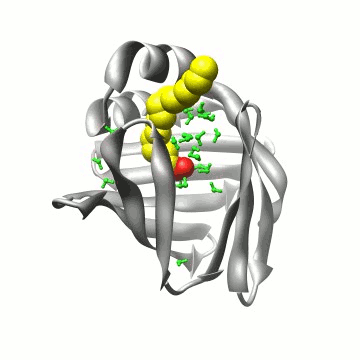
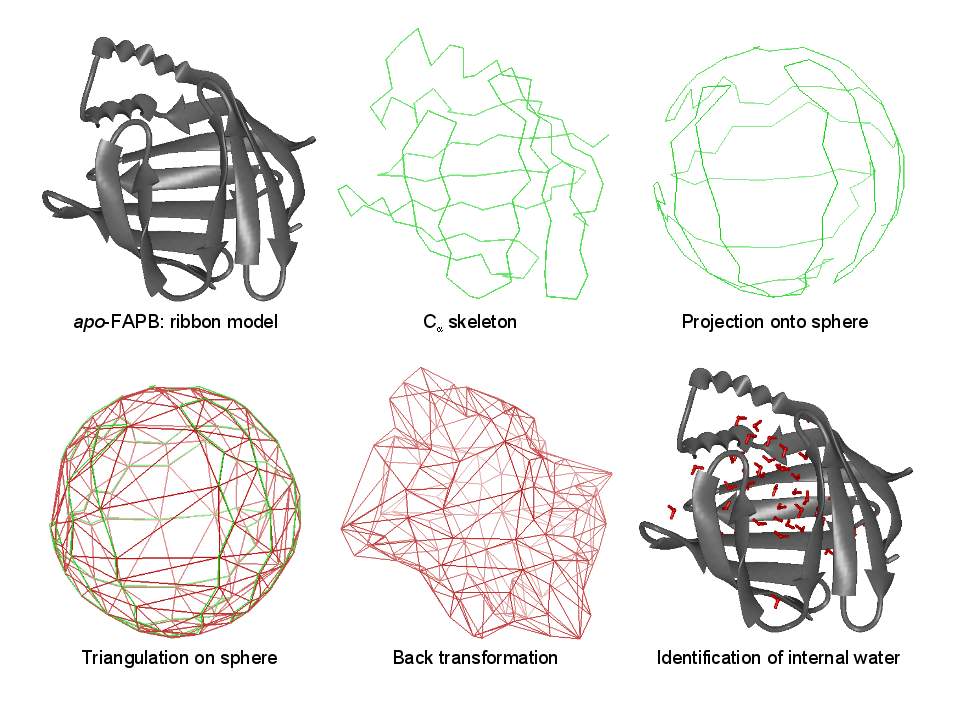
A simulation of FABP in
water. The protein carries a large water-filled cavity in the
interior. How can we extract this internal water?
|
Essentially, we represent the protein barrel by its Cα skeleton, triangulate it, and determine all water molecules inside the polyhedron. |
Some details on the algorithm. The triangulation exploits locality and can thus be performed in linear time. |
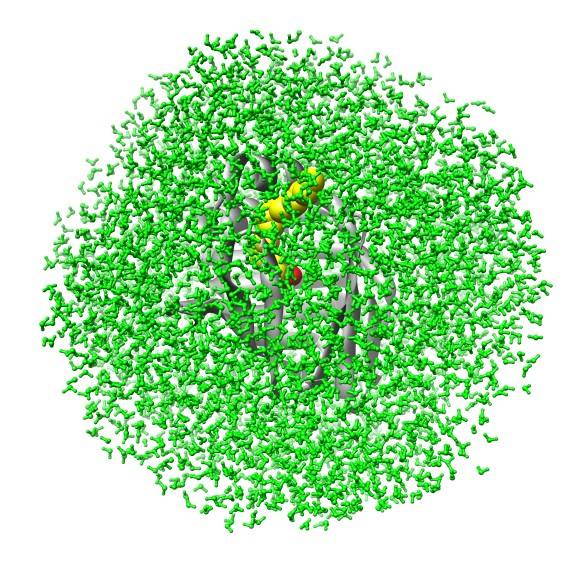
|
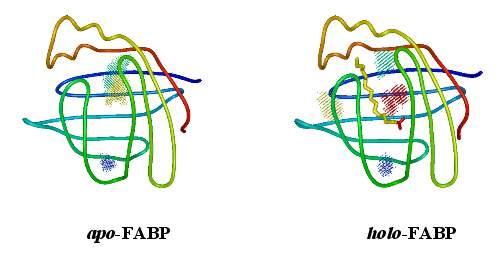
Biomolecular simulation: FABP |
Using the above algorithm, we may
analyze the entire trajectory
and identify the distribution of 3 (apo) and 4 (holo)
water molecules which in NMR experiments have been found to be
particularly immobile,
|
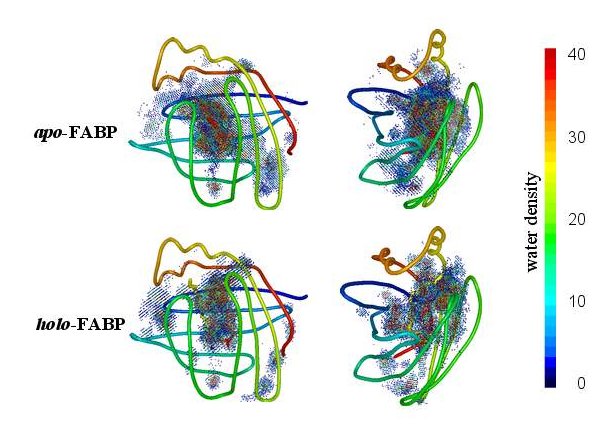
or analyze the entire interior water density |
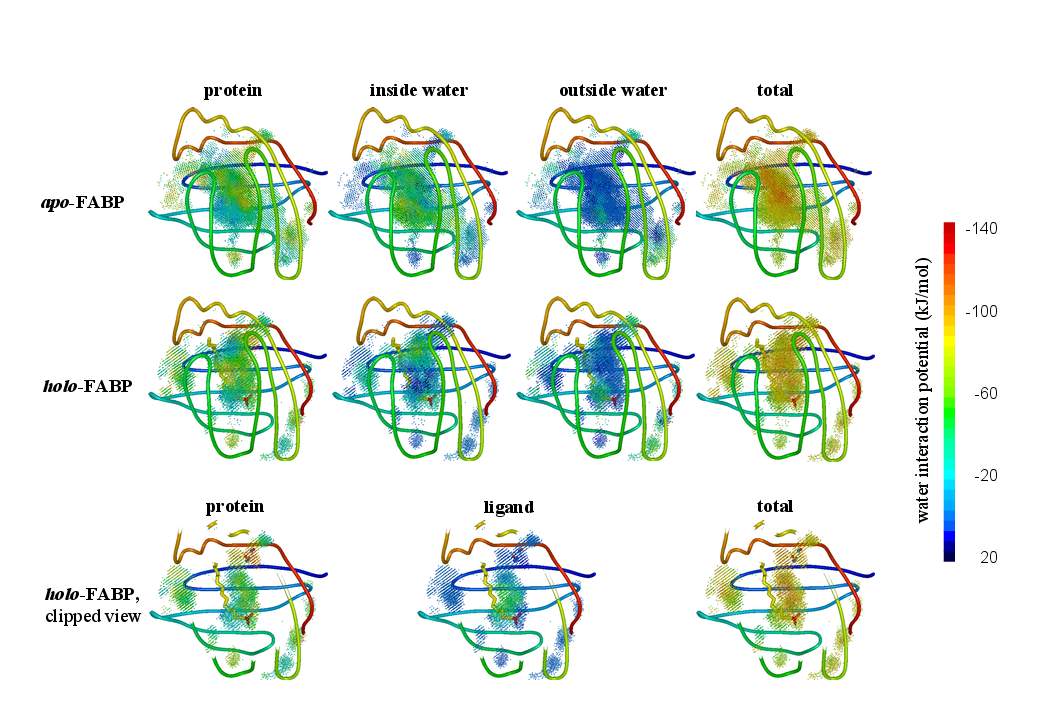
or even time-resolved interaction potentials with other water, with protein residues, and with the ligand to improve our understanding of the internal water dynamics. |
|
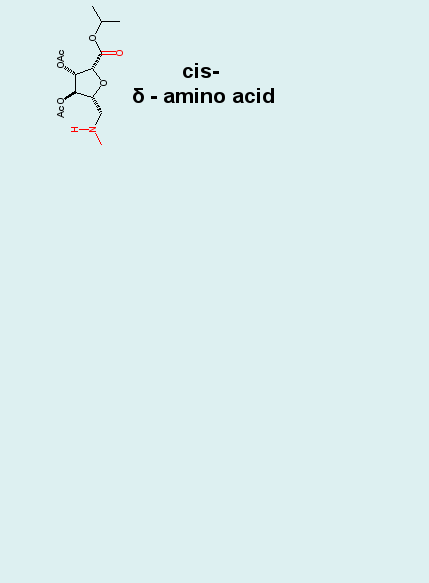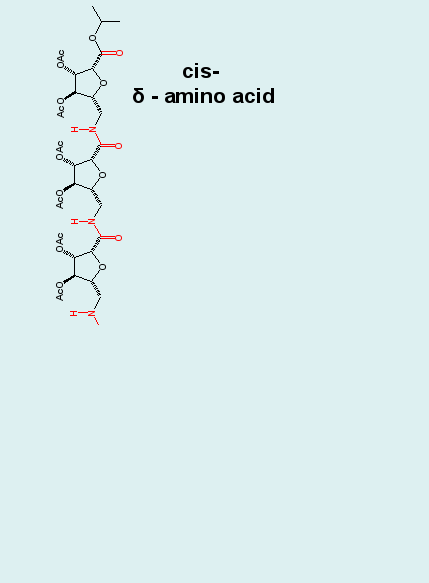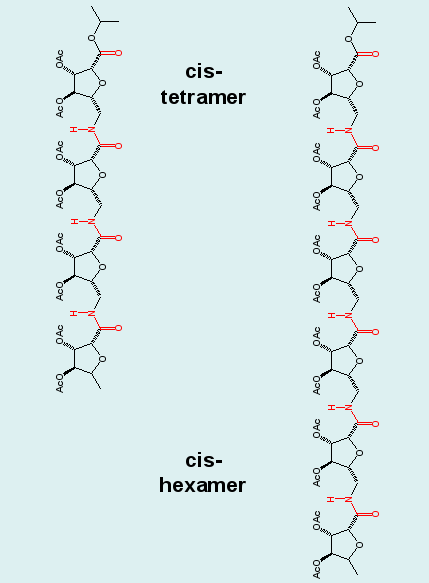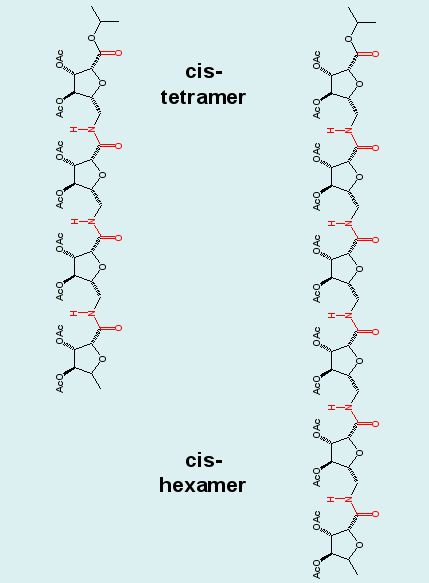
Biomolecular simulation: Carbopeptoids |
Carbopeptoids are homooligomers of sugar-containing peptides,
and they serve as rigidified peptide models with potential
applications as drugs that block protein-protein interactions
and inhibit enzyme catalysis.
|
MD simulations
reproduce experimentally (NOE) derived distance constraints.
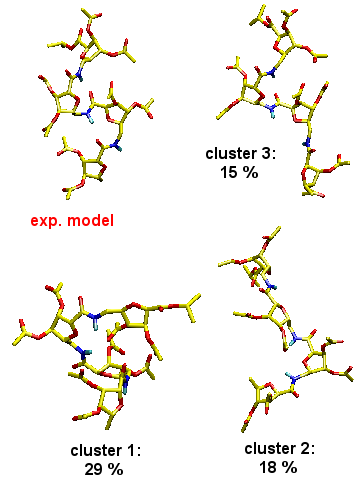
Cluster analyses of MD trajectories demonstrates, however,
that the experimentally postulated helical structure is only
one of several dominating structural motifs comprising the
entire ensemble, and that the unfolded state is in fact not
structureless. Such insight is hard if not impossible to obtain
from experiment alone.
|
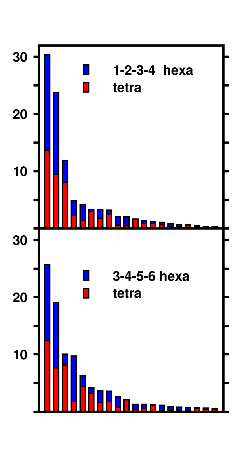
Cluster analysis combining the ensembles of the tetrapeptide and equally long blocks of the hexapeptide demonstrates the repetition of structural motifs in longer peptide chains, a result, that was postulated in experimental studies. Note the "overlapping" (blue/red) clusters in the graph. |
|
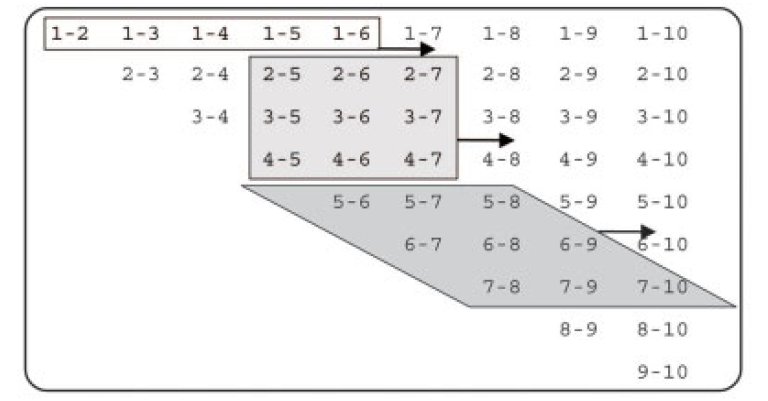
MD simulation software: Pair list algorithms |
MD simulations often apply a distance-cutoff for pair potentials,
and the scan of the atom pair matrix is one of the very
time-critical parts of such an MD simulation. While linear-scaling
grid-cell techniques become efficient for very large system sizes,
improved double-loop algorithms are beneficial for intermediate
sizes often considered in current-day simulations.
|
Here we take advantage of the fast processor cache found in modern CPUs and replace the row-wise atom pair scan (unshaded) by a window scan (shaded) which can process a number of pairs that scales quadratically, rather than linearly, with the number of atoms loaded into cache memory. The triangular atom-pair matrix may be reordered to become rectangular, in which case all rhombic windows become quadratic. |

|
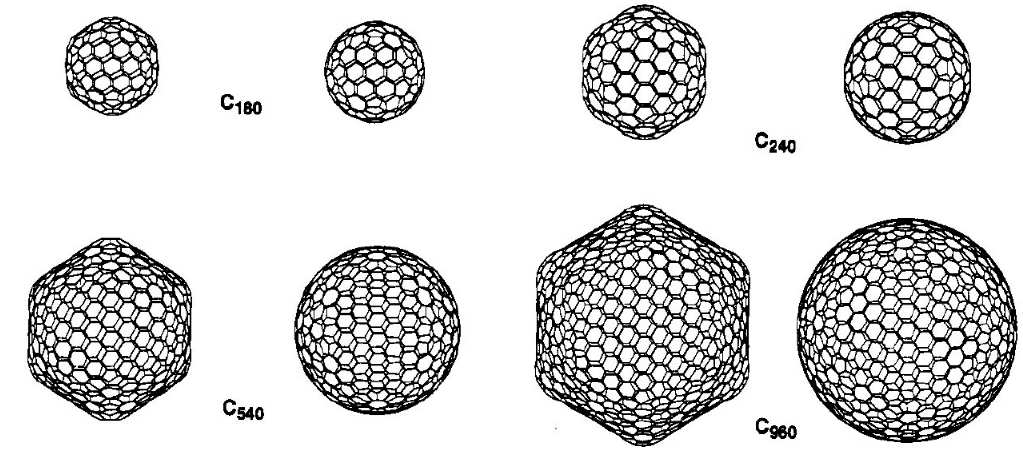
Giant fullerenes |
Fullerenes were discovered in the mid-80's and have attracted
a lot of attention as new allotropes of carbon. The prototype
buckminsterfullerene, C60, is spherical due to its
high symmetry.
|
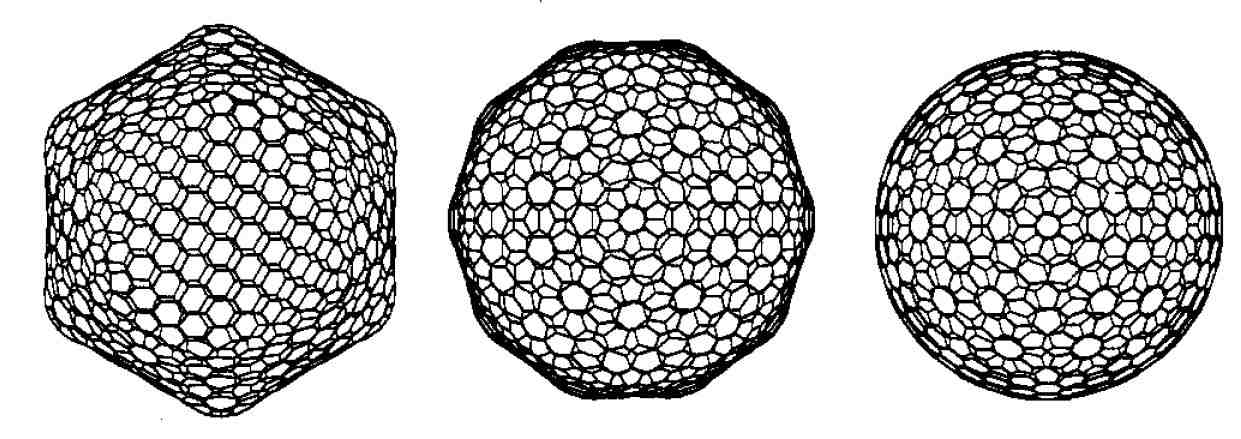
Despite earlier claims, however, our
semiempirical calculations
have shown that larger fullerenes of icosahedral symmetry
prefer facetted over spherical shapes. These results were
confirmed by more rigorous
density functional calculations . The picture above shows
the facetted form of C960 from two different
perspectives and a hypothetical spherical alternative. |